解析ソフトも販売しているようですが、こういう意味のないパスワードはソースをいじってさくっと解除しましょう。
[ブックの保護]や[シートの保護]のパスワードを忘れてしまったら | Excel 2019 | 初心者のためのOffice講座
処理をpythonで実装したものは以下を参照
解析ソフトも販売しているようですが、こういう意味のないパスワードはソースをいじってさくっと解除しましょう。
[ブックの保護]や[シートの保護]のパスワードを忘れてしまったら | Excel 2019 | 初心者のためのOffice講座
処理をpythonで実装したものは以下を参照

Panelでファイルインプット、アウトプットを実装しました。
これがあるとWebアプリを作るときに活用できます。
でも、なかなか癖が強いですね。
今回はjsonファイルを例に取り扱っています。 テキストファイルと画像ファイルは、同様に実装できるようです。
ポイントは、
です。
開発者のPhilipp RudigerさんがPanelの開発に力を入れているようなので仕様は今後変わる可能性が高いです。(PyDev of the Week: Philipp Rudiger - Mouse Vs Python参照)
import pandas as pd from io import StringIO import panel as pn pn.extension()
pn.__version__
#'0.11.3'
def getsio(val): df = pd.read_json(val) sio = StringIO() d = df.to_json(sio) sio.seek(0) return sio file_input = pn.widgets.FileInput(accept='.json') obj = pn.Column(file_input, '') def update(event): if file_input.value is not None: file_output = pn.widgets.FileDownload(getsio(file_input.value), embed=True, filename='output.json') obj[-1] = file_output file_input.param.watch(update, 'value') obj.servable()
補足:geopandasでgoejsonを取り扱う場合
String型ではなく、Byte型になるようなので上記のgetsio関数を以下のようにする必要があるようです。
from io import StringIO, BytesIO def getsio(val): df = gpd.read_file(val.decode('utf-8')) sio = BytesIO() d = df.to_file(sio, driver='GeoJSON', encoding='UTF-8') sio.seek(0) return sio
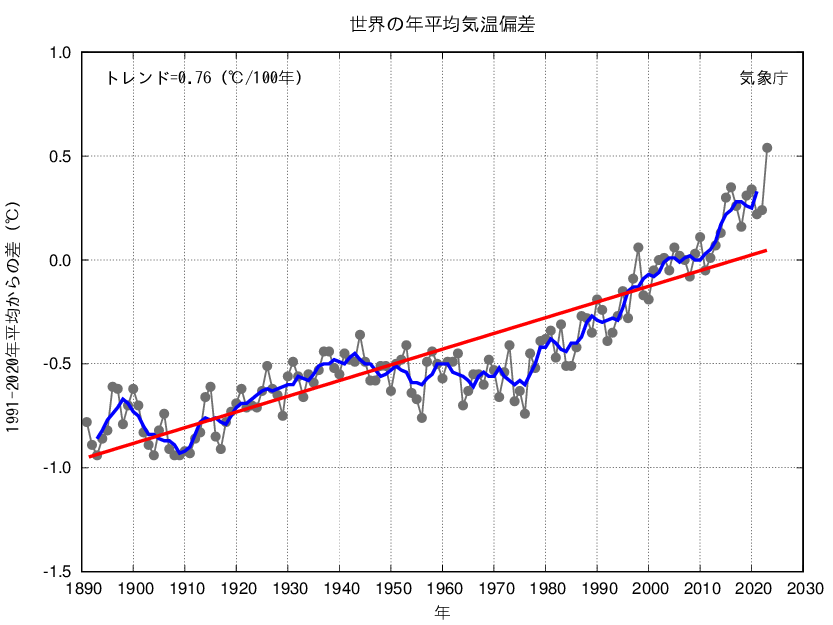
最近暑過ぎて頭がおかしくなったので、かつてより日本の夏は暑くなったを調べてみました。
気象庁の観測データより、神戸地点 のデータを用いて分析を行う。 (なぜ神戸かというと子供の頃に住んでいたからです。)
上記データより、1897~2020年の7、8月の日データ(最高、最低、平均)を使用する。 そのデータを、各年の7、8月の2ヶ月平均値を図化した。なお、図中の黒線は5年移動平均を示す。
これらのデータより、夏季の気温の経年変化は以下のとおりである。
次に7、8月の最高気温が35℃以上を記録した日数を図化した。
暑過ぎて訳の分からない記事を書いた感想です。
pandasで窓関数を適用するrollingを使って移動平均などを算出 | note.nkmk.me
computational-sediment-hyd.hatenablog.jp
観測データ等をpandasで取り扱う場合に欠測値等が文字列になっていることがよくあります。
この処理が結構苦労するのですが、現時点での最良案をまとめます。
もっと良い方法があれば教えて下さい。
サンプルデータは以下の気象庁の公開データの形式とする。準正常値の場合は)が後ろに付きます。
import pandas as pd import numpy as np
df = pd.DataFrame({'A': [29.0, 26.5, 28.9, 33.1, '30.0 )'],
'B': [31.3, 31.3, 32.4, 32.1, 34.3],
'C': [ 29.5, 27.7, 32.5, '30.3 )', 26.1]})
df
| A | B | C | |
|---|---|---|---|
| 0 | 29.0 | 31.3 | 29.5 |
| 1 | 26.5 | 31.3 | 27.7 |
| 2 | 28.9 | 32.4 | 32.5 |
| 3 | 33.1 | 32.1 | 30.3 ) |
| 4 | 30.0 ) | 34.3 | 26.1 |
dfp = df.select_dtypes(include='object')
dfp
| A | C | |
|---|---|---|
| 0 | 29.0 | 29.5 |
| 1 | 26.5 | 27.7 |
| 2 | 28.9 | 32.5 |
| 3 | 33.1 | 30.3 ) |
| 4 | 30.0 ) | 26.1 |
手順は以下のとおりです。
dfp = dfp.astype(str) p = '[-+]?(\d+\.?\d*|\.\d+)([eE][-+]?\d+)?' out = np.empty(0) for n in dfp.columns: #数字以外の文字を抽出 a = dfp[dfp[n].str.fullmatch(p)==False][n].values out = np.append( out, np.unique(a) ) out = np.unique(out) out
array(['30.0 )', '30.3 )'], dtype=object)
今回は、通常の数値と同様に取り扱うため、カッコを削除して数値に変換します。
for n in out : nn = float( n.replace(')','').strip() ) df = df.replace(n, nn) df
| A | B | C | |
|---|---|---|---|
| 0 | 29.0 | 31.3 | 29.5 |
| 1 | 26.5 | 31.3 | 27.7 |
| 2 | 28.9 | 32.4 | 32.5 |
| 3 | 33.1 | 32.1 | 30.3 |
| 4 | 30.0 | 34.3 | 26.1 |
# 数値に戻す df= df.astype(float)
df.dtypes
A float64
B float64
C float64
dtype: object
for n in out : df = df.replace(n, np.nan)
ようやくまとめることができたので記事にします。

浅水流近似した一次元流れの式(Saint-Venentの式)を自然河道断面(一般断面とも呼ばれる)に対応できるように河道横断面積分した次の式を基本とします。
以下の条件よりソースコードを作成しています。
def UnSteadyflow(sections, A, Q, H, Abound, Qbound, dt): g = float(9.8) imax = len(A) Anew, Qnew, Hnew = np.zeros(imax), np.zeros(imax), np.zeros(imax) ie = np.zeros(imax) Beta = np.zeros(imax) # continuous equation for i in range(1, imax-1) : dx = 0.5*(sections[i-1].distance - sections[i+1].distance) Anew[i] = A[i] - dt * ( Q[i] - Q[i-1] ) / dx Anew[imax-1] = Abound Anew[0] = Anew[1] # Anew[0] = (Anew[1] - A[1]) + A[0] for i in range(imax) : s = sections[i] Hnew[i], _, _ = s.A2HBS(Anew[i], H[i]) arr = s.calIeAlphaBetaRcUsubABS(Q[i], H[i]) ie[i] = arr[0] Beta[i] = arr[2] # moumentum equation for i in range(1, imax-1): ic, im, ip = i, i-1, i+1 dxp = sections[ic].distance - sections[ip].distance dxm = sections[im].distance - sections[ic].distance dxc = 0.5*(sections[im].distance - sections[ip].distance) Cr1 = 0.5*( Q[ic]/A[ic] + Q[ip]/A[ip] )*dt/dxp Cr2 = 0.5*( Q[ic]/A[ic] + Q[im]/A[im] )*dt/dxm dHdx1 = ( Hnew[ip] - Hnew[ic] ) / dxp dHdx2 = ( Hnew[ic] - Hnew[im] ) / dxm dHdx = (float(1.0) - Cr1) * dHdx1 + Cr2 * dHdx2 Qnew[ic] = Q[ic] - dt * ( Beta[ic]*Q[ic]**2/A[ic] - Beta[im]*Q[im]**2/A[im] ) / dxc \ - dt * g * Anew[ic] * dHdx \ - dt * g * A[ic] * ie[ic] Qnew[imax-1] = Qnew[imax-2] Qnew[0] = Qbound return Anew, Qnew, Hnew
全てのコードはこちら
対象河川は8909090001です。
対象範囲は下図のとおりで観測データの存在状況より、3.000~17.600としています。
水文水質データベースより、流量観測所Y地点の1996年以降で最大流量を記録した2012年7月12日の出水を対象としました。
下流端はO地点の観測水位を与え、上流端は計算範囲上流端の少し下流に位置するY地点の観測流量を与える。
上流端流量および下流端水位は下図のとおりです。
全コードは少し長くなるので主要な部分のみ解説します。
計算は、初期条件計算と本計算の2つに分類できます。
まず、初期時点の流量、水位を条件とした不等流計算により水位を設定し、それを初期条件とした非定常計算による助走計算を20時間実施し、その結果を初期値として与えた。
# nonuniform flow Qt = np.full(len(chD2U), Qup[0], dtype=np.float64) Huni = model.NonUniformflow(chD2U, Qt, Hdown[0]) Auni = np.array( [chD2U[i].H2ABS(hh)[0] for i, hh in enumerate(Huni)] ) A0 = Auni[0] # unsteady flow : 20hr Q = np.full_like(Auni, Qup[0]) A, H = Auni[::-1], Huni[::-1] for n in range(1, int(3600*20/dt)): A, Q, H = model.UnSteadyflow(chU2D, A, Q, H, A0, Qup[0], dt)
上記の初期条件、前述の境界条件より計算する。
nmax = len(chU2D) ntmax = len(Qup) Amat, Qmat, Hmat = np.zeros((ntmax, nmax)), np.zeros((ntmax, nmax)), np.zeros((ntmax, nmax)) Amat[0], Qmat[0], Hmat[0] = A, Q, H for n in range(1, ntmax): A0, _, _ = chU2D[-1].H2ABS(Hdown[n]) A, Q, H = model.UnSteadyflow(chU2D, A, Q, H, A0, Qup[n], dt) Amat[n], Qmat[n], Hmat[n] = A, Q, H
出力はxarrayを用いてNetCDF形式のファイルを作成する。
gdfsectsorted = gdfsect.sort_values('distancefromDB', ascending=False) ds = xr.Dataset( {'A': (['t','x'], Amat) ,'Q': (['t','x'], Qmat) ,'H': (['t','x'], Hmat) ,'zbmin': (['x'], [c.zbmin() for c in chU2D] ) } , coords={'x':gdfsectsorted['distancefromDB'].values , 't':dfhydroip.index.values} ,attrs = {'name':gdfsectsorted['name'].values.tolist()} ) dout = ds.to_netcdf(r'calout.nc') del dout
全てのコードはこちら
python3.0以降であれば、環境依存は無いはずですが、jitclassのロード方法がバージョンにより若干異なるようです。詳細は、以下の記事を参照。
computational-sediment-hyd.hatenablog.jp
いきなり不等間隔、複断面河道のモデルですが、近似リーマン解法、期待してます。
computational-sediment-hyd.hatenablog.jp
computational-sediment-hyd.hatenablog.jp
computational-sediment-hyd.hatenablog.jp

この手のものを作ったのは何パターン目だろうか。。。
大量のデータ処理が必要だったので作りました。出来は過去1かも。
グラフとテーブルを並べてどちらでも編集できるようにしました。
使い込んでバグが取れたら公開しようかなと。
河川のデータは、元データがエラーを含んでいたり、計算に適さない仕様になっていたりするのですが、機械的に処理するのが難しくて結局手作業になってしまいます。
処理したデータの版管理をできるようなシステムを作りたいなと思いつつ仕様を考えると悩んでしまいます。
こういうのを作っているとよくGUIが好きだと思われますが基本的には苦手で科学技術計算のほうが好きです。
でも、河川の計算では計算データセットをつくる前処理に膨大な時間を要するため、こういうツールが無いときついです。何とかならないかな。。。。。
pandasでjsonのread-write
holoviews:dynamic map
holoviews:dynamic mapのstream
holoviews:pointdraw
panel - widgetsの記述パターン(わかりやすい)
gifの作成
最近よく使うスクリプトなので備忘録的にまとめました。
conda create -y -n tmp python=3.7 conda activate tmp conda install -y -c conda-forge rioxarray conda install -y -c conda-forge gdal conda install -y -c conda-forge jupyter
那賀川(code:8808060001)のALBデータより 04GG542_0.5gを使用する。
過去記事(欠損したグリッド標高テキストデータからgeotiffを作成するpythonスクリプト - 趣味で計算流砂水理)と同様。
データサイズを小さくするため、単位系をmからcmに変換し、geotiffをint32型とする変更を加えた。
作成したファイルは「04gg542_0.5g.tif」
こちらからダウンロード可能。
import numpy as np import xarray as xr
pl = [98891.63181796, 104393.37756069]
# read raster ds = xr.open_rasterio('04gg542_0.5g.tif') # get raster properties dy, dx = ds.res xOrigin =ds.x.values[0] - 0.5*dx yOrigin =ds.y.values[0] + 0.5*dy ynum = ds.shape[1] xnum = ds.shape[2] z = ds.values[0] nepsg = int(ds.attrs['crs'][-4:])
xind = np.floor( (pl[0] - xOrigin)/dx ).astype(int) yind = np.floor( (yOrigin - pl[1])/dy ).astype(int) print(z[yind, xind]/100)
21.7
作成したコードはこちら
# 左岸杭座標 pl = [98891.63181796, 104393.37756069] # 右岸杭座標 pr = [ 99438.53777557, 104214.89229045]
pl = np.array(pl) pr = np.array(pr) # 測線の長さ L = np.linalg.norm(pr - pl) # 単位ベクトルe e = (pr - pl)/ L # 杭の外側(堤内地側)にLex延伸する。 Lex = 50 # 測線上にdelta間隔の点群を発生させる。 delta = 0.5 dl = np.arange(-Lex, L+Lex, delta) points = np.array( [pl+e*dlp for dlp in dl] )
indx = np.floor( (points[:,0] - xOrigin)/dx ).astype(int) indy = np.floor( (yOrigin - points[:,1])/dy ).astype(int) Z = np.array([z[iy, ix]/100 for ix,iy in zip(indx, indy)])
import holoviews as hv hv.extension('bokeh')
g = hv.Curve((dl,Z))
hv.save(g,'ALBcrosssect.html')
g
作成したコードはこちら
国土地理院の標高データのうちは5m間隔のLPデータから作成されているDEM5Aを使用する。
データの取得は以下のライブラリを使用する。
import libgsidem2el as gsi import geopandas as gpd from shapely.geometry import Point
delta = float(5) dl2 = np.arange(-Lex, L+Lex, delta) points2 = np.array( [pl+e*dlp for dlp in dl2] )
gdf = gpd.GeoDataFrame(geometry=[Point(p[0],p[1]) for p in points2], crs={'init': 'epsg:'+str(nepsg)}) # geopandas : change coordinate gdf = gdf.to_crs(epsg=6668)
dem5 = gsi.libgsidem2el('DEM5A') Z2 = [] for go in gdf.geometry.values: zt = dem5.getEL(go.x, go.y, zoom = 15) if(zt == 'e') or (zt == 'outside') : zt = float(-9999) Z2.append(zt) Z2 = np.array(Z2, dtype=float)
ALB:0.5mメッシュとLP:5mメッシュで大局的にはそんなに変わらない気がします。
河岸とか堤防とかをみる場合は細かい方がいいかもという感じです。
g = hv.Curve((dl,Z), label='ALB') * hv.Curve((dl2,Z2), label='LP') hv.save(g,'ALBandLP.html') g
computational-sediment-hyd.hatenablog.jp