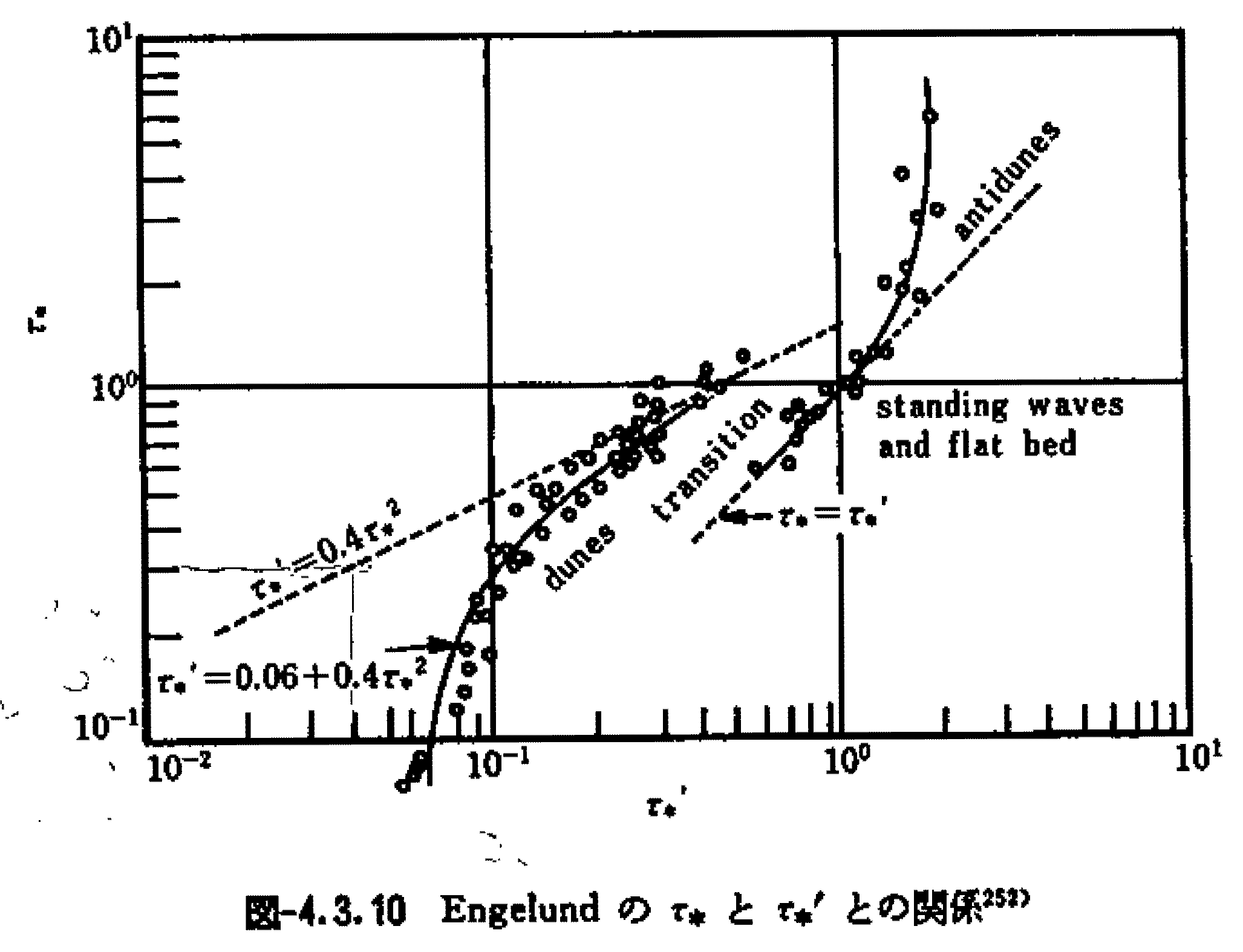
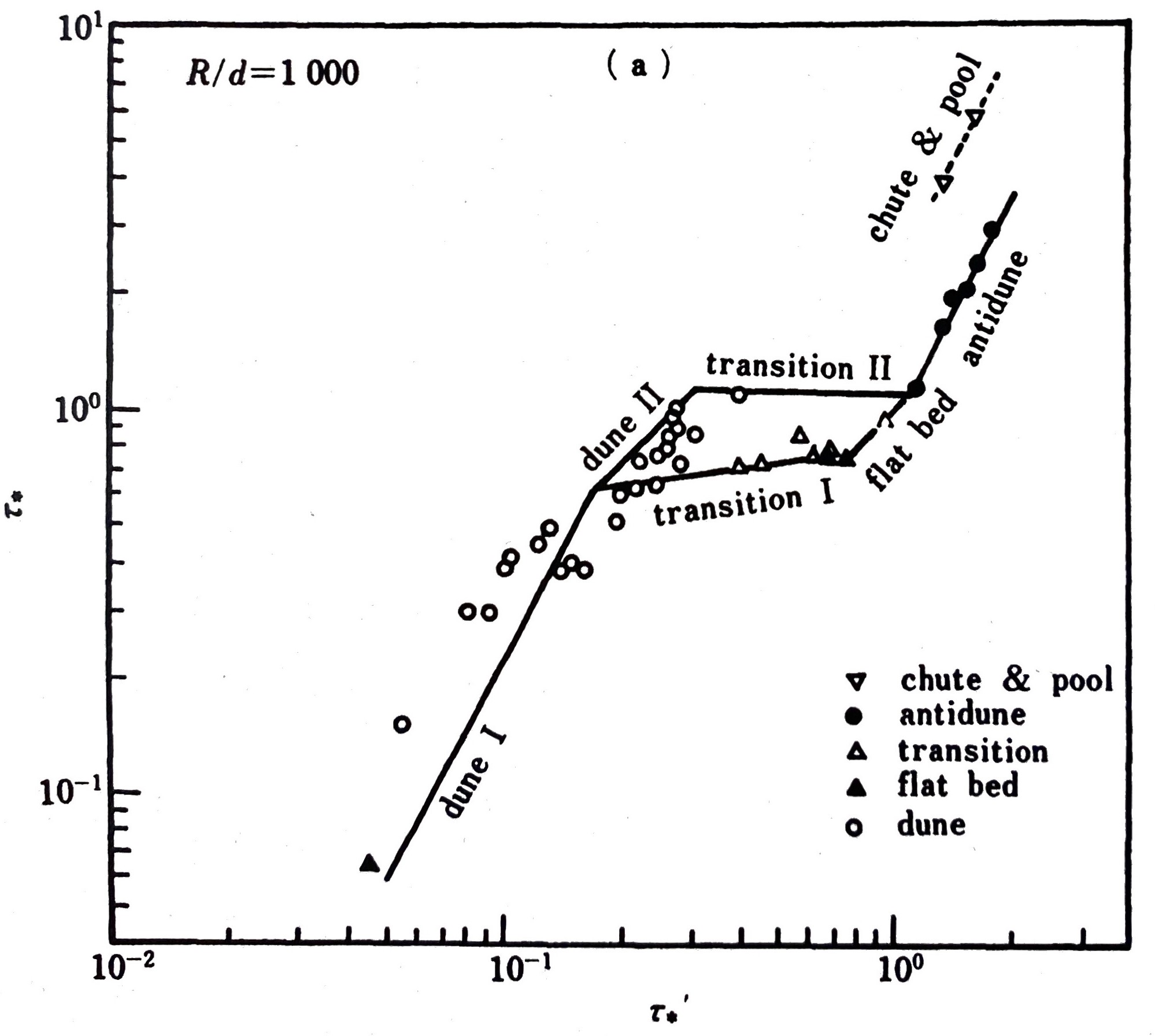
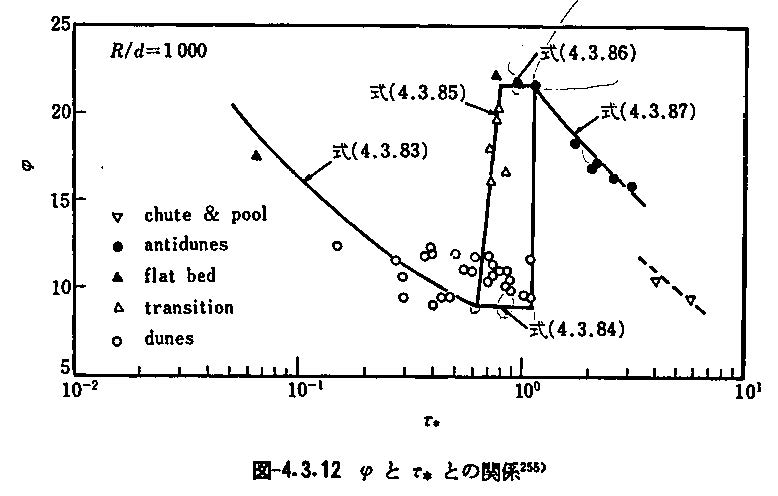
The English version is available here
はじめに
非線形問題の最適化に最もよく使用されるL-BFGS法(記憶制限BFGS法、BFGS法は準ニュートン法の解法の一つ)について書きます。準ニュートン法なので勾配法ですね。
ディープラーニングでは確率的勾配降下法(力技!!)が使用されますが、最適化問題やディープラーニング以外の機械学習でもL-BFGS法はよく使われています。
しかし、L-BFGS法のオープンライブラリはあまり多くないです。
その理由としては、私が思うのものは、
- 汎用的なものが書きづらい。用途に合わせたチューニングが必要。
- コーディングが泥臭い。不安定なモデルのためエラー処理が山程必要。
です。
そんな感じで、本記事では汎用的なものでなく、L-BFGS法の主たる部分であるヘッセ行列の更新の部分を主に書いておきます。
L-BFGS法の導出
ググると山程引っかるのでここでは省略します。いくつか有用な記事をリンクしておきます。
私は上の2つを参照しました。
L-BFGS法はだからメモリが節約できるのか! - あらびき日記
Limited-memory BFGS - Wikipedia
L-BFGS法の更新式を導出 - ysk24ok.github.io
3分でわかるL-BFGS - Kotaro's blog
書籍では以下が参考になります。
リンク
ちょっと今回の話とは異なりますが、L-BFGS法の高速化の論文も面白いので貼っておきます。
https://papers.nips.cc/paper/5333-large-scale-l-bfgs-using-mapreduce.pdf
L-BFGS法の実装
上記の数式を元にそのままコーディングします。いつもどおりpython使います。
import numpy as np
def lbfgs(x, f, g, stepsize, maxiterate, memorysize, epsilon):
def searchdirection(s, y, g):
q = -np.copy(g)
num = len(s)
a = np.zeros(num)
if num==0 : return q
for i in np.arange(num)[::-1]:
a[i] = np.dot(s[i], q)/np.dot(y[i], s[i])
q -= a[i]*y[i]
q = np.dot(s[-1], y[-1]) / np.dot(y[-1], y[-1]) * q
for i in range(num) :
b = np.dot(y[i], q) / np.dot(y[i], s[i])
q += ( a[i] - b ) * s[i]
return q
outx = []
s = np.empty((0, len(x)))
y = np.empty((0, len(x)))
xold = x.copy()
gold = g(xold)
J1 = f(xold)
mmax = memorysize
sp = stepsize
print( 'f= ', J1 )
outx.append(xold)
for num in range(maxiterate):
if np.linalg.norm(gold) < epsilon :
print('g=',np.linalg.norm(gold))
break
d = searchdirection(s, y, gold)
sp = stepsize*0.01 if num == 0 else stepsize
xnew = xold + sp * d
gnew = g(xnew)
J2 = f(xnew)
J1 = J2
si, yi = xnew - xold, gnew - gold
if len(s) == mmax :
s = np.roll(s, -1, axis=0)
y = np.roll(y, -1, axis=0)
s[-1] = si
y[-1] = yi
else:
s = np.append(s, [si], axis=0)
y = np.append(y, [yi], axis=0)
xold, gold = xnew, gnew
print( 'iterate= ', num, 'f= ', J1, ' stepsize= ', sp )
outx.append(xold)
return xold, outx
引数は、最適化する変数xと評価関数fとその勾配g、それに加えて、ステップ幅やイテレーションの最大値や収束条件、ヘッセ行列更新時に過去何回分の履歴を用いるかのパラメータmemorysizeを与えます。
コーディングの難しいところは特に無いですが、面白いところは配列の大きさがmemorysizeを超えた時点でnumpyのroll関数で配列の順番を更新しているところです。
私はイテレーションの1回目はステップ幅を十分に小さく取ります。今回の計算例の場合は大きくても問題ないですが、評価関数が微分方程式の場合は発散する可能性があるためです。
計算例
次式を例にL-BFGS法を適用してみます。

Xの初期値はx=-2.5,y=0で、最適値はx=1,y=0です。パラメータは適当です。ステップ幅は1です。
%%time
f = lambda x : 5.0*x[0]**2.0 - 6.0*x[0]*x[1] + 5.0*x[1]**2 - 10.0*x[0] + 6.0*x[1]
g = lambda x : np.array( [ 10.0 * x[0] - 6.0 *x[1] -10.0, 10.0 * x[1] - 6.0 *x[0] + 6.0 ] )
x = np.array( [-2.5, 0.0] )
xx, out = lbfgs(x, f, g, stepsize=1.0, maxiterate=20, memorysize=5, epsilon=10.0**(-8))
print(xx)
> f= 56.25
> iterate= 0 f= 40.864 stepsize= 0.01
> iterate= 1 f= -1.3307052922247742 stepsize= 1.0
> iterate= 2 f= -3.1273465839434973 stepsize= 1.0
> iterate= 3 f= -4.999999466916309 stepsize= 1.0
> iterate= 4 f= -4.999999999941274 stepsize= 1.0
> iterate= 5 f= -4.999999999999999 stepsize= 1.0
> iterate= 6 f= -5.0 stepsize= 1.0
> g= 8.580967415593408e-10
> [1.00000000e+00 1.53469307e-10]
> Wall time: 4 ms
イテレーションは6回で収束します。その過程を図化するとこんな感じです。
scipy.optimize.fmin_l_bfgs_bとの比較
scipyには、L-BFGS法scipy.optimize.fmin_l_bfgs_bが、用意されています。一応それと比較しておきます。
%%time
f = lambda x : 5.0*x[0]**2.0 - 6.0*x[0]*x[1] + 5.0*x[1]**2 - 10.0*x[0] + 6.0*x[1]
g = lambda x : np.array( [ 10.0 * x[0] - 6.0 *x[1] -10.0, 10.0 * x[1] - 6.0 *x[0] + 6.0 ] )
out2 = []
def callback(xk):
out2.append(xk)
print(xk)
x = np.array( [-2.5, 0.0] )
out2.append(x)
xx, y, d = opt.fmin_l_bfgs_b(f, x, fprime=g, m=5, iprint=0, epsilon=10.0**(-8), maxiter=20, maxls=1, callback=callback)
> [-1.64250707 -0.51449576]
> [ 0.10902424 -1.00977252]
> [ 0.4446687 -0.73580975]
> [ 1.00115755 -0.00273162]
> [ 1.00005759e+00 -1.68279906e-05]
> [1.00000095e+00 7.64484423e-07]
> Wall time: 3 ms
計算時間、イテレーションの回数、収束の過程はほとんど一緒ですね。
メモ
scipy.optimize.fmin_l_bfgs_b
の中身は、次のライブラリで数千行に及ぶごりごりのFortran90です。(かつてこれを使ってFortran03のコードを書きました。難解すぎて死にそうでした。)
L-BFGS-B Nonlinear Optimization Code
もちろん高機能で幅広いケースに対応してますが、単純な問題なら自作の数十行のコードで十分です。
単純な最急降下法との比較も示しておきます。ステップ幅を0.05、0.1と2ケースを書きました。
2ケースともにイテレーションは20回まで計算しました。
%%time
f = lambda x : 5.0*x[0]**2.0 - 6.0*x[0]*x[1] + 5.0*x[1]**2 - 10.0*x[0] + 6.0*x[1]
g = lambda x : np.array( [ 10.0 * x[0] - 6.0 *x[1] -10.0, 10.0 * x[1] - 6.0 *x[0] + 6.0 ] )
x = np.array( [-2.5, 0.0] )
out3 = []
out3.append(x)
for _ in range(20):
xx = x - 0.05*g(x)
out3.append(xx)
x = xx.copy()
x = np.array( [-2.5, 0.0] )
out4 = []
out4.append(x)
for _ in range(20):
xx = x - 0.1*g(x)
out4.append(xx)
x = xx.copy()
2ケースともにいいところまで収束しますが、その経路は大きく異なります。
このように最急降下法の場合はステップ幅が重要になります。
考察とまとめ
- 単純なL-BFGS法の実装について書きました。実問題に通用するコードを書こうとするとはもうちょっと複雑になりますが、基本はわかるかと思います。
- L-BFGS法の利点の一つは勾配降下法の重要なステップ幅の設定が適当で良い点である。これは非常に重要な点で、汎用コードを見てるとコードの大半はステップ幅の設定に関する部分(ラインサーチ)になるので、これを省略できることは有利になります。
- また、ラインサーチではArmijo条件とWolf条件をよく使いますが、その際にfやgの計算を複数回実施します。単純な例では問題ないですが、流体問題の最適化ではfやgの計算1回に数十分~数時間かかることもよくあります。そのため、L-BFGS法は計算時間短縮の点からもメリットがあります。
- 今後は、流体問題のL-BFGS法の適用例(ラグランジュの未定乗数法かな)も書いてみようと思います。
github.com
computational-sediment-hyd.hatenablog.jp
computational-sediment-hyd.hatenablog.jp