本記事はGitHub、nbviewer、Colabでも公開しています。
※Colabの解説記事はこちら



導入
「河道計画検討の手引き」に示される合流による水位上昇の計算方法について解説します。
この手法は、室田 明, 多田 博登:一次元水面形解析における合流点モデルに関する研究が元になっています。
計算式
合流による水位上昇量の計算方法の概要を以下に示す。
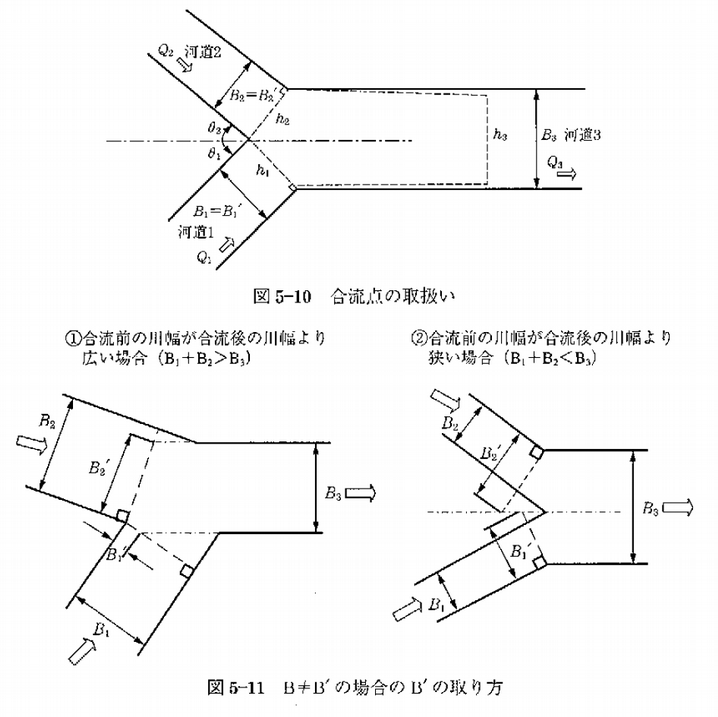
手引と同様に合流後河道の流向軸の運動量保存則は以下のとおりとなる。
コントロールボリュームの考え方が若干複雑なため、詳細は元論文を参考にされたい(時間ができたときにまとめます)。
ここに、 :水の密度、
:水の密度、 :重力加速度、
:重力加速度、 :流量、
:流量、 :水路幅、
:水路幅、 :水深、
:水深、 :合流角度(下図参照)、
:合流角度(下図参照)、 :運動量補正係数、
:運動量補正係数、 :修正した川幅(下図参照)、添字1,2,3は河道1,2,3(下図参照、ここでは1:本川、2:支川とする)の諸量である。
:修正した川幅(下図参照)、添字1,2,3は河道1,2,3(下図参照、ここでは1:本川、2:支川とする)の諸量である。
元論文のとおり を条件として式変形を行うと以下のとおりとなる。
を条件として式変形を行うと以下のとおりとなる。
ここに、フルード数 とする。
とする。
として整理すると、
のとおり、 の三次方程式となる。これを解くことによって水位上昇量を計算する。
の三次方程式となる。これを解くことによって水位上昇量を計算する。
なお、元論文では (角度補正した合流前川幅の和が合流後川幅と等しい)を前提条件としているが、前出の手引には記載されていない。
(角度補正した合流前川幅の和が合流後川幅と等しい)を前提条件としているが、前出の手引には記載されていない。
本記事では簡易的に、 として水位上昇量の計算を行った。
として水位上昇量の計算を行った。
テスト計算
計算モデル
- 三次方程式はnp.rootsで解く。
- 上記の解のうち、実数かつ1以上(水位上昇量のため)のものを水位上昇量とする。
- 正しい条件を与えると解は1または0個になる。
参考 三次方程式の計算方法:https://west-village-tech.com/cubic_equation/
import numpy as np
def caldhConfluence(Q1Q3 ,Q2Q3 ,B3B1 ,B3B2 ,Theta1 ,Theta2 ,Fr):
g = (Q2Q3)**2*B3B2*np.cos(Theta2*np.pi/180) \
+ (Q1Q3)**2*B3B1*np.cos(Theta1*np.pi/180)
x = np.roots([1,0,-1-2*Fr**2,2*g*Fr**2])
x2 = x[np.iscomplex(x)==False]
x3 = x2[np.where(x2>=1.0)]
if len(x3) == 0:
ans = np.nan
elif len(x3) == 1:
ans = x3[0].real
else:
print('error')
ans = np.nan
return ans
合流角度および合流前流量比の感度分析
合流角度は以下の3ケースを設定する。
合流前流量比は以下の3ケースを設定する。また、川幅はRegime theory( )により設定する。よって、式中の係数は以下のとおりとなる。
)により設定する。よって、式中の係数は以下のとおりとなる。
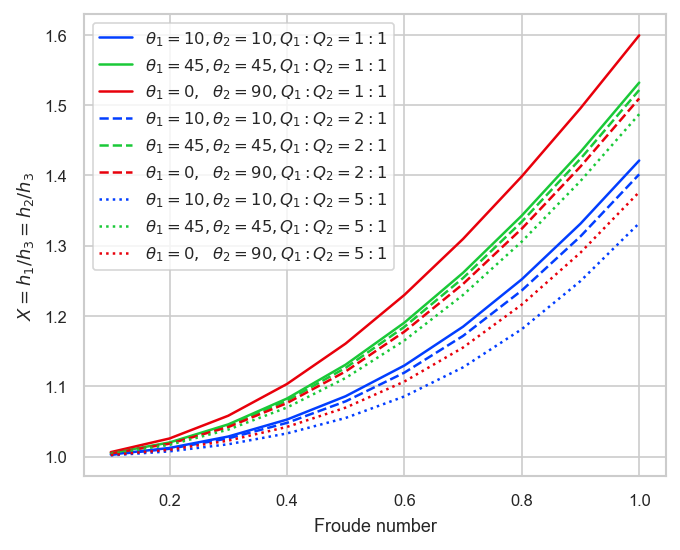
これらを組み合わせ9ケースについて合流後のフルード数を0.1~1.0まで変化させた場合の水位上昇量の計算結果を以下に示す。
これらより、以下の点が確認できる。
- フルード数が大きい程水位上昇量が大きい
- 合流角度が大きい程水位上昇量が大きい。(CaseA,B)
- 合流流量比は1:1に近い程水位上昇量が大きい。
- 直角合流CaseCの場合、合流流量が大きいCase1では水位上昇量は大きいが、Case3で相対的に水位上昇量が小さくなっている。
Fr = np.arange(0.1,1.01,0.1)
Q1Q3=1/2
Q2Q3=1/2
B3B1=np.sqrt(2)
B3B2=np.sqrt(2)
dhoutA1 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=10 ,Theta2=10 ,Fr=f) for f in Fr]
dhoutA2 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=45 ,Theta2=45 ,Fr=f) for f in Fr]
dhoutA3 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=0 ,Theta2=90 ,Fr=f) for f in Fr]
Q1Q3=2/3
Q2Q3=1/3
B3B1=np.sqrt(3/2)
B3B2=np.sqrt(3)
dhoutB1 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=10 ,Theta2=10 ,Fr=f) for f in Fr]
dhoutB2 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=45 ,Theta2=45 ,Fr=f) for f in Fr]
dhoutB3 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=0 ,Theta2=90 ,Fr=f) for f in Fr]
Q1Q3=5/6
Q2Q3=1/6
B3B1=np.sqrt(6/5)
B3B2=np.sqrt(6)
dhoutC1 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=10 ,Theta2=10 ,Fr=f) for f in Fr]
dhoutC2 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=45 ,Theta2=45 ,Fr=f) for f in Fr]
dhoutC3 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=0 ,Theta2=90 ,Fr=f) for f in Fr]
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context='paper', palette="bright", style="whitegrid", font_scale=0.9)
%matplotlib inline
fig = plt.figure(figsize=(5, 4), dpi=150)
ax = fig.add_subplot()
ax.plot(Fr,dhoutA1, label='$ \\theta_1 =10,\\theta_2 =10, Q_1:Q_2=1:1$' , c='b', ls='-')
ax.plot(Fr,dhoutA2, label='$ \\theta_1 =45,\\theta_2 =45, Q_1:Q_2=1:1$' , c='g', ls='-')
ax.plot(Fr,dhoutA3, label='$ \\theta_1 = 0,\,\,\,\, \\theta_2 =90, Q_1:Q_2=1:1$', c='r', ls='-')
ax.plot(Fr,dhoutB1, label='$ \\theta_1 =10,\\theta_2 =10, Q_1:Q_2=2:1$' , c='b', ls='--')
ax.plot(Fr,dhoutB2, label='$ \\theta_1 =45,\\theta_2 =45, Q_1:Q_2=2:1$' , c='g', ls='--')
ax.plot(Fr,dhoutB3, label='$ \\theta_1 = 0,\,\,\,\, \\theta_2 =90, Q_1:Q_2=2:1$', c='r', ls='--')
ax.plot(Fr,dhoutC1, label='$ \\theta_1 =10,\\theta_2 =10, Q_1:Q_2=5:1$' , c='b', ls=':')
ax.plot(Fr,dhoutC2, label='$ \\theta_1 =45,\\theta_2 =45, Q_1:Q_2=5:1$' , c='g', ls=':')
ax.plot(Fr,dhoutC3, label='$ \\theta_1 = 0,\,\,\,\, \\theta_2 =90, Q_1:Q_2=5:1$', c='r', ls=':')
ax.set_xlabel('Froude number')
ax.set_ylabel('$X=h_1/h_3=h_2/h_3$')
ax.legend()
plt.show()
合流前川幅の感度分析
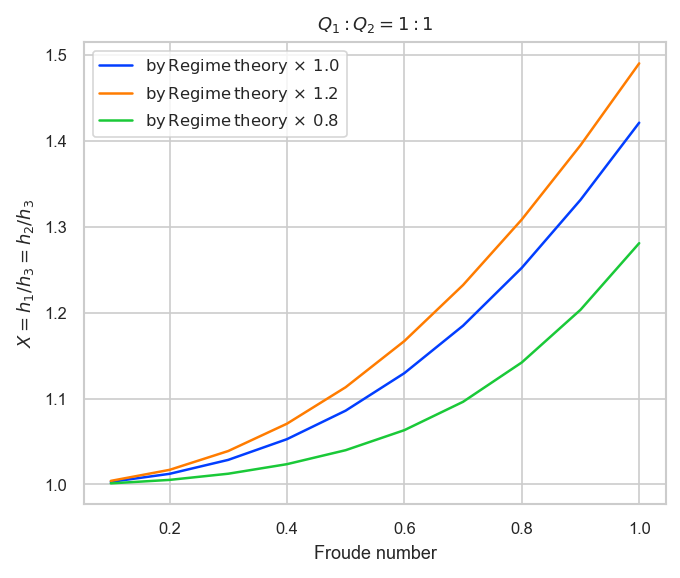
次に川幅の影響について感度分析を行った。
ケースとして、合流前川幅がRegime theory()の1.2倍、0.8倍を設定した。
式中の係数は以下のとおりとなる。ここでは、 のみとした。
のみとした。
これらについて合流後のフルード数を0.1~1.0まで変化させた場合の水位上昇量の計算結果を以下に示す。
これらより、以下の点が確認できる。
- 合流前川幅が大きいほど水位上昇量が大きくなる。これは流速が小さくなるためである。
- 合流前川幅を小さくする場合、本計算条件では約0.7倍以下でが1以下、つまり水位が上昇しない条件になる(本モデルではnanを返す)。これは、合流前の流れが射流になるためである。
Fr = np.arange(0.1,1.01,0.1)
Q1Q3=0.5
Q2Q3=0.5
B3B1=np.sqrt(2)
B3B2=np.sqrt(2)
dhout1 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=10 ,Theta2=10 ,Fr=f) for f in Fr]
B3B1=5/6*np.sqrt(2)
B3B2=5/6*np.sqrt(2)
dhout2 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=10 ,Theta2=10 ,Fr=f) for f in Fr]
B3B1=5/4*np.sqrt(2)
B3B2=5/4*np.sqrt(2)
dhout3 = [caldhConfluence(Q1Q3,Q2Q3,B3B1,B3B2,Theta1=10 ,Theta2=10 ,Fr=f) for f in Fr]
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context='paper', palette="bright", style="whitegrid", font_scale=0.9)
%matplotlib inline
fig = plt.figure(figsize=(5, 4), dpi=150)
ax = fig.add_subplot()
ax.plot(Fr,dhout1, label='$\mathrm{by\,Regime\,theory}\, \\times \,1.0$')
ax.plot(Fr,dhout2, label='$\mathrm{by\,Regime\,theory}\, \\times \,1.2$')
ax.plot(Fr,dhout3, label='$\mathrm{by\,Regime\,theory}\, \\times \,0.8$')
ax.set_xlabel('Froude number')
ax.set_ylabel('$X=h_1/h_3=h_2/h_3$')
ax.set_title('[tex:Q\_1:Q\_2=1:1]')
ax.legend()
plt.show()
github.com
参考文献
リンク
リンク
リンク
関連記事
computational-sediment-hyd.hatenablog.jp