我々の業界でも地形データの解像度の増加に伴ってGeoTIFFの使用頻度は増えています。 点群密度の増加によってGeoTIFFの容量も大きなるため、データベースの構築やアプリケーションでの使用を考えると、適切な圧縮アルゴリズムを選択する必要があります。
過去記事( 画像処理のど素人がまとめたpythonによるTIFF圧縮形式の比較 - 趣味で計算流砂水理 Computational Sediment Hydraulics for Fun Learning )でも紹介しましたが、Guide to GeoTIFF compression and optimization with GDAL(2018)にGeoTIFFの圧縮アルゴリズムに関する知見が非常によくまとまっています。 元サイトはかなり詳しく書かれておりますが、若干読みづらいところがありますので、翻訳して要点を整理しておきます。
- 圧縮アルゴリズムの比較
- 使用される圧縮アルゴリズムには、None、PACKBITS、Deflate、LZW、LZMA、ZSTDがあります。
- Deflate、LZW、ZSTDは予測子(Predictor)を使用することで圧縮効率が向上します。
- ベンチマークテスト
- 3つのテストファイル(byte.tif、int16.tif、float32.tif)を使用して、圧縮率と読み書き速度を測定。
- ZSTDは高速で、特に低圧縮レベルで優れた性能を発揮します。
- 追加の考慮事項
- タイル化(Tiling)やLERC(Limited Error Raster Compression)などのオプションが紹介されています。
- マルチスレッド圧縮やキャッシュ設定など、パフォーマンス向上のための設定も説明されています。
- 結論
- データの種類に応じた適切な圧縮アルゴリズムと設定を選択することが重要。
- ZSTDとLERCの最新バージョンは非常に有望で、実際のシナリオでのテストが期待されます。
計画
さまざまなデータタイプとアルゴリズムの圧縮率および読み書き速度を、それぞれの設定オプションでテストするためのベンチマークを実行します。
テストファイル
- 一般的に使用されるデータタイプの3つのテストファイルを作成しました。:
byte.tif、int16.tif、float32.tif。 - 各ファイルは、非圧縮状態で約50MBになるようにトリミングされています。ダウンロードリンクや詳細情報についてはノートを参照してください。
参考までに、ズームアウトした状態のByte、Int16、およびfloat32の画像は次のようになります。
アルゴリズムと作成オプション
次の圧縮アルゴリズムをテストします。
- なし
- PACKBITS
- Deflate
- LZW
- LZMA
- ZSTD
Deflate、LZW、およびZSTDアルゴリズムは、前の値との差分のみを保存する方法である予測子の使用をサポートしています。テストできる予測子設定は3つあります。
- 予測子なし(1、デフォルト)
- 水平方向の差分(2)
- 浮動小数点予測(3)
予測子は、データに空間的な相関があり、ピクセルの値が隣接するピクセルと似ている場合に特に効果的です。浮動小数点予測は、名前が示すように、浮動小数点データにのみ使用できます。
ZSTDおよびDeflateアルゴリズムは、ZLEVELおよびZSTD_LEVEL作成オプションを通じてカスタム圧縮レベルをサポートしています。圧縮レベルを下げると、圧縮率を犠牲にしてアルゴリズムの速度が向上し、圧縮レベルを上げると、速度を犠牲にして圧縮率が向上します。ZSTDおよびDeflateアルゴリズムを、低、中、高の圧縮レベルでテストします。
ベンチマークで使用されるすべての異なるテストと対応する作成オプションは、config.iniに定義されています。
ベンチマーク設定
- ベンチマークは、クリーンなマシンとローカルSSDボリュームを確保し、バックグラウンドで他のものが動作しないようにするために、一時的なAWS
i3.largeEC2インスタンス内のDockerコンテナ内で実行されます。 - GDALは
Dockerfileからソースビルドされ、バージョン2.4.0devが使用されます。これは、予測子オプションを使用してLERCおよびZSTD圧縮を完全にサポートする最初のバージョンです。
すべてのテストコマンドは、メインの
gtiff_benchmark.py
スクリプトによって順番に実行され、各テストの組み合わせに対して異なる
gdal_translate
コマンドをperf statを使用して呼び出します。例えば、
perf stat -x ^ -r 5 gdal_translate \\
-q int16.tif output.tif \\
-co COMPRESS=DEFLATE \\
-co PREDICTOR=2
ベンチマーク結果
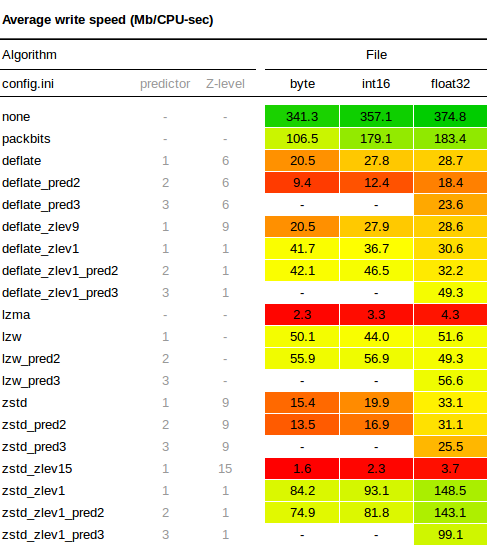
書き込み速度
書き込みテストでは、対応する圧縮設定で各50MBファイルを書き込むのに必要な時間を測定します。以下の表の速度は元のファイルサイズに対する相対速度であり、1秒間に圧縮できる生データのMB数を示しています。例えば、50MBのファイルが0.5秒で書き込まれた場合、以下に100MB/sの速度が報告されます。結果は次の通りです。
結果:
- ZSTDおよびDeflateの圧縮レベル1では、デフォルトレベルよりも書き込み速度が大幅に速くなります。
- デフォルトの圧縮では、DeflateはZSTDよりもわずかに速く書き込みますが、低い圧縮レベルではZSTDが一般的に速くなります。
- LZWは非常に一定しており、デフォルト設定で良好に動作し、ZSTDおよびDeflateの両方よりも速いです。低い圧縮レベルでは、Deflateが追いつき、ZSTDが書き込み速度でLZWを上回ります。
- Deflateで予測子を使用すると、他のアルゴリズムよりも書き込み速度が低下するようです。
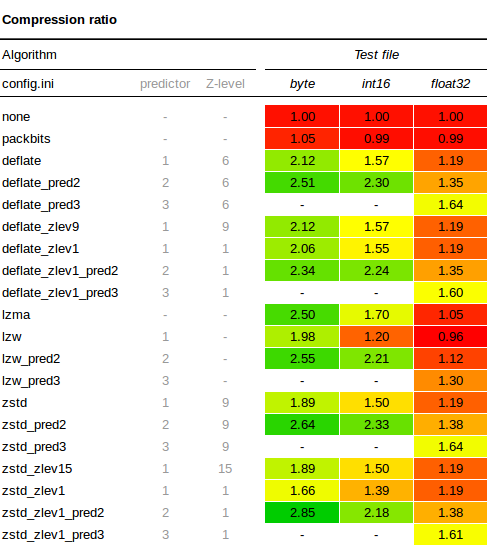
圧縮率
圧縮率テストの結果表は次の通りです。
結果:
- PREDICTOR=2を使用すると、デフォルトの予測子なしよりも常に良い圧縮率が得られます。この場合、DEMおよび土壌マップの値の空間相関によるものかもしれませんが、多くの地理データには何らかの空間相関があるため、他の多くのデータセットでも同様の結果が見られることに驚きません。
- ByteおよびInt16は一般的にFloat32データタイプよりも圧縮が良好です。浮動小数点データを使用している場合は、データをByteまたはInt16データタイプに変換できるかどうかを調査する価値があります。これにより、スペースが少なくなり、圧縮が良好になります。データによっては、浮動小数点データを特定の係数(10、100、または1000)で乗算し、整数をByteまたはInt16として保存し、データを視覚化またはさらに処理する必要がある場合にのみ選択した係数で再度除算することができます。また、この記事のさらに下のLERCセクションも参照してください。
- 浮動小数点予測子PREDICTOR=3は、浮動小数点データの圧縮率を大幅に向上させます。浮動小数点予測子でデータを書き込む際のパフォーマンスペナルティもないようですので、Float32データには非常に安全な選択です。
- 適切な予測子を使用すると、ZSTD、Deflate、およびLZWの圧縮率の違いはそれほど顕著ではありません。
読み取り速度
読み取り速度テストの結果表は次の通りです。
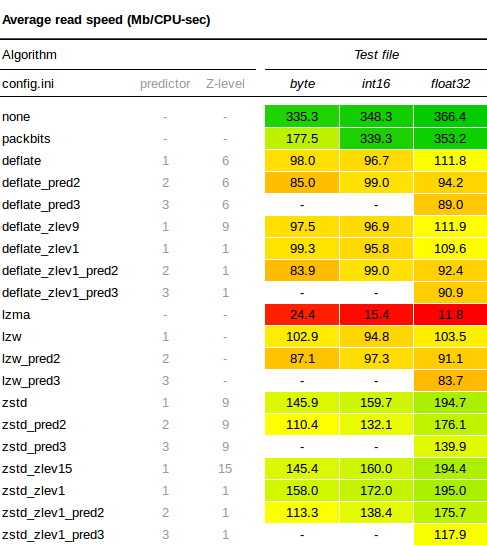
ZSTDはその高速性で評判通りの性能を発揮し、LZWおよびDeflateの両方よりも優れた性能を示しています。圧縮にZレベルを使用しても、解凍速度にはあまり影響しないようです。予測子の使用は解凍を少し遅くするようですが、それほど大きな影響はありません。
さらなる考慮事項
このセクションでは、パフォーマンスに影響を与える可能性のある追加の問題やGDAL設定について説明します。(一部のみ記載。全項目は元ページを参照ください。)
タイリング
作成オプションTILED=YESが有効になっている場合、データは行ごと(ストリップ)ではなくブロック(タイル)で保存および圧縮されます。タイルのサイズは、BLOCKXSIZE=nおよびBLOCKYSIZE=n作成オプションを使用して構成できます。常にファイル全体を読み取るか、1ピクセルずつ読み取る場合には、タイリングはあまり役に立ちません。なぜなら、それぞれすべてまたは1つのタイルまたはストリップのみを解凍する必要があるからです。
限定誤差ラスター圧縮(LERC)
LERCはGDAL 2.4以降で利用可能であり、データの精度を犠牲にしてより良い圧縮率を得るために設計されています。LERCの主な特徴は、MAX_Z_ERROR作成オプションを使用して、アルゴリズムが許容される損失の程度を正確に定義できることです。LERCはCOMPRESS=LERCとして単独で使用することも、ZSTDまたはDeflateと組み合わせてCOMPRESS=LERC_ZSTDおよびCOMPRESS=LERC_DEFLATEとして使用することもできます。
オーバービュー
オーバービューは、元のデータの複製バージョンですが、低解像度にリサンプリングされています。これは、データのズームアウトバージョンをレンダリングまたは読み取る際に役立ち、これらのオーバービューを即座に計算するにはデータが多すぎる場合に便利です。
画像の圧縮
画像の圧縮はこの記事の範囲外ですが、完全を期すためにそれについても言及したいと思います。圧縮しようとしているデータが画像(航空写真、真カラー衛星画像、またはカラーマップ)で構成されている場合、JPEGのような損失のあるアルゴリズムを使用して、はるかに改善された圧縮率を得ることができます。ただし、JPEGのような損失のあるアルゴリズムは、精度が重要なデータの圧縮には適していないため、このベンチマークでは省略しました。
結論
この記事が、GeoTIFFドライバーのさまざまな圧縮アルゴリズムの性能とGeoTIFFファイルから追加のパフォーマンスを引き出すために使用できる設定オプションについての徹底的な概要を提供できたと思います。
最も重要なのは、実験を続け、この記事の技術を使用してデータとアクセス方法に最適なものを見つけることです。自分のデータの種類を認識し、適切な予測子とZレベルを使用して迅速なパフォーマンス向上を図りましょう。
Notes and References
- テストファイルは次の通りです: soilgrids.orgからの抽出(Byte)、SRTMタイルから抽出されたDEM(Int16)、およびUSGS National Elevation Datasetからの高解像度DEM(Float32)。テストファイルはここからダウンロードできます。
- このテーマに関する追加情報については、以下のブログ投稿もご覧ください:Rob EmanueleによるGDAL compression options against NED data、Kersten ClaussによるGeoTIFF compression comparisonおよびPaul RamseyによるGeoTIFF compression for dummies。
- ベンチマークのコードはhttps://www.github.com/kokoalberti/geotiff-benchmarkで入手できます。
- webページのmarkdown化は、 Copy as Markdown - Chrome ウェブストアを使用。